文本处理工具
cat
hexdump
1
2
3
|
hexdump -C -n 512 /dev/sda
# -C 显示ASCII码
# -n 数字 字节长度
|
more
只能向下翻页,使用空格键或 Enter 键逐步向下滚动。
一次性加载整个文件内容,因此在查看大文件时可能会遇到卡顿。
less:比 more 更好用
持双向滚动。可以使用方向键或 Page Up / Page Down 键向上和向下翻页,允许更方便的文件浏览。
采用逐页加载机制,尤其适合查看大文件,性能更佳,不会一次性加载全部内容。
head
1
|
head -n 10 FILE # 前10行输出
|
tail
1
|
tail -n 10 FILE # 后10行输出
|
tr
-d :删除所有出现在 SET1 中的字符。
-s :将连续重复出现的字符(由 SET1 和 SET2 指定或其他条件)压缩为单一出现。常和字符替换同时使用,以减少重复字符。
-c :对 SET1 集合进行补集操作,也就是说对不在 SET1 中的字符进行操作。(例如,tr -dc '0-9' 会删除所有不在0到9之间的字符。)
-t :截断 SET1 或 SET2,使得两者长度相同进行处理。该选项在部分系统中可能为默认行为。
常见用法示例
-
大小写转换
将标准输入中的小写字母全部转换为大写字母:
1
|
cat file.txt | tr '[:lower:]' '[:upper:]'
|
或者:
1
|
tr 'a-z' 'A-Z' < file.txt
|
-
删除特定字符
删除文本中的所有数字字符:
删除所有换行符(将文本行连接成一行):
-
压缩重复字符
将连续的空格压缩为单个空格:
将连续出现的换行符压缩为一个:
-
删除非数字字符
保留数字,删除其他所有字符:
1
|
tr -cd '0-9' < file.txt
|
这里 -c 是对字符集取反,-d 是删除该集合字符,因此 -cd '0-9' 即保留数字并删除非数字。
-
替换制表符为空格
有时文件中含有制表符(\t),想将其转换为单个空格:
-
多种字符间的映射
将 abc 转换为 123:
1
|
tr 'abc' '123' < file.txt
|
当 SET1 长于 SET2 时,多出来的字符会映射为 SET2 的最后一个字符。例如:
1
|
tr 'abcd' '12' < file.txt
|
a 映射到 1,b 映射到 2,c 和 d 都映射到 2。
cut:按列抽取文本
1
2
3
4
5
6
|
-d # 指定分隔符
-f # 要显示列
--output-delimiter="+" # 输出是用+替代分隔符
head -n 2 <<< $(ifconfig) | tail -n 1| cut -d ' ' -f 10
10.0.0.14
|
paste:合并文件,行行合并
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
seq 1 10 > 1.txt
printf "%s\n" {a..g} > 2.txt
paste 1.txt 2.txt
1 a
2 b
3 c
4 d
5 e
6 f
7 g
8
9
10
|
1
2
|
-d # 设定分割符
-s # 一列合成一行
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
paste -d : 1.txt 2.txt
1:a
2:b
3:c
4:d
5:e
6:f
7:g
8:
9:
10:
paste -d : -s 1.txt 2.txt
1:2:3:4:5:6:7:8:9:10
a:b:c:d:e:f:g
|
xargs
xargs 可以将管道或标准输入(stdin)数据转换成命令行参数,也能够从文件的输出中读取数据。
xargs 一般是和管道一起使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
-d # 指定分隔符
-E # 指定结束符
-l N # 一次性读取 N 行
-n # 一次执行用多少参数
-p # 执行前确认
-r # 输入为空,不执行
-t # 显示过程
-i # 使用{}占位符
-P n # 并发 n 执行
-0|--null # 用 assic 中的 0 或 null 作分隔符
echo user{1..5} |xargs -t -n 1 useradd
seq 60 | xargs -i -P3 you-get https://www.bilibili.com/video/BV1KX4y1S7dT?p ={}
ls
'a b' f-1.txt f-2.txt f-3.txt
# 'a b',被拆分为
find -type f | xargs ls
ls: cannot access './a': No such file or directory
ls: cannot access 'b': No such file or directory
./f-1.txt ./f-2.txt ./f-3.txt
find -type f -print0 |xargs -0 ls
'./a b' ./f-1.txt ./f-2.txt ./f-3.txt
ls
1 2 3 4 5
ls * | xargs -n 1 -i {} rename '{}' '{}.txt' {}
ls
1.txt 2.txt 3.txt 4.txt 5.txt
|
文本分析工具
wc:文本数据统计
1
2
3
4
5
|
-l # 只统计行数
wc story.txt
39 237 1901 story.txt
行数 单词数 字节数
|
sort:文本排序
1
2
3
4
|
-u # 去重
-k 数字 # 指定排序列
-r # 倒序
-n # 以数字大小排序
|
uniq:去重
1
2
3
|
-c # 显示重复数
-d # 仅显示重复的行
-u # 仅显示不重复的行
|
diff:比较文件
1
|
diff -u f1.txt f2.txt > f.patch
|
patch:应用差异文件,用于版本更新
1
2
3
4
5
6
7
|
-b # 备份
# 到处差异文件
diff -u 100 102 > 100_102.patch
# 将 100 更新为 102
patch -b 100 100_102.patch
|
cmp:对比二进制文件
grep:正则全局搜索并打印行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
-E # 使用 ERG 正则
-F # 不正则
-G
-P
-v # 取反,显示没有匹配到的行
-e pattern0 -e pattern1 # 匹配 0 或 1
-f FILE # 从文件中读取匹配规则
-i # 忽略大小写
-w # 只匹配完整的单词;"root"(不匹配部分字符串,如 rootuser)
-B N # 显示匹配到的前 N 行;before
-A N # 显示匹配到的后 N 行;after
-C N # 显示匹配到的前后 N 行
-n # 显示匹配到的行号
-H # 显示匹配到的文件名
-o # 仅显示匹配到的内容
-d # 查找目录
-D # 查找设备文件
-r # 递归目录,不处理软链接
-R # 递归目录,处理软链接
-L|--files-without-match # 显示没有匹配上的文件名,只显示文件名
-l|--files-with-matches # 显示匹配上的文件名,只显示文件名
-c|--count # 统计匹配到的行数
grep -nir 关键字 /路径
# 大范围文件中,快速检索内容,修改配置
|
1
2
3
4
5
6
7
8
9
|
grep -v nologin /etc/passwd
grep -v "#" /etc/fstab # 不看注释
grep -n bash /etc/passwd
grep -C 2 root /etc/passwd # -A;-B
grep root /etc/passwd | grep bash # 且匹配
|
1
2
3
4
5
6
7
8
9
|
df | grep '^/dev/sd'
# ^表示行首匹配
df | grep '^/dev/sd' | grep -oE '\< [0-9]{1,3}%' | grep -Eo '[0-9]+'
# -o 只输出匹配到的
# -E 启动正则
# \< 匹配开头
# [0-9]{1,3} 1-3 个 0-9 的数字
# % 有百分比
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
[root@loong ~]# ifconfig | grep -E '[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}' -o
10.0.0.14
255.255.255.0
10.0.0.255
00:50:56:36 ****
7417145 ****
35391370 ****
127.0.0.1
255.0.0.0
192.168.122.1
255.255.255.0
192.168.122.255
52:54:00:5 ****
[root@loong ~]# ifconfig | grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' -o
10.0.0.14
255.255.255.0
10.0.0.255
127.0.0.1
255.0.0.0
192.168.122.1
255.255.255.0
192.168.122.255
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
\<
\>
# 单词边界符
# \< root 匹配 “root” 出现在单词开头的情况。
# root \> 匹配 "root" 出现在单词结尾的情况。
# \< root \> 表示“完整匹配单词 root”,避免包含其他字符的词被误匹配。
grep -E "^(.*)\>.* \<\1$" /etc/passwd
# 去看正则位置锚定
# ^
# (.*)
# \1
# $
|

sed
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到 最后一行。
一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。
1
2
3
4
5
6
7
8
9
10
11
|
sed option '<匹配条件> [动作]; [动作]' pathOfFile
-n # 静默模式
-i # 直接修改文件;-i.bak,以 bak 文件备份原文件
-i.bak
-r # 扩展正则
# 带时间戳备份
sed -i."$(date +%Y%m%d%H%M%S).bak " 's/old_text/new_text/g' filename.txt
-ni #危险组合,会清空文件
|
匹配条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 数字行数
空 # 表示所有行
n # 表示第 n 行
n, m # n 到 m
n,+m # n 到 n+m
$ # 尾行
~ # 表示步进
1~2 # 奇数行
2~2 # 偶数行
# 关键字匹配
'/关键字/'
# /可用@,#,! 替换
/关键字 1/,/关键字 2/ # 匹配到 1 的行,到匹配到 2 的行
n,/关键字 1/
|
动作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
p # print
Ip # 忽略大小写,print
d # 删除
a[\]text # append
i[\]text # insert
c[\]text # 替换匹配到的整行
s### # 替换匹配的内容
w file # 保存至 file
r file # 读取 file
= # 显示行号
q # 结束 sed
# 上面的动作应该在参数为-i 的时候使用,不然的话不会有效果
|
1
2
3
|
nihao sed1 sed2 sed3
nihao sed4 sed5 sed6
nihao sed7 sed8 sed9
|
打印
1
2
3
4
5
6
7
|
sed '2p' sed.txt -n
nihao sed4 sed5 sed6
sed -n '/^root/p' /etc/passwd
sed -n '/bash$/p' /etc/passwd
sed -n -e '1p' -e '3p' sed.txt
|
替换
1
2
3
4
5
6
7
8
9
|
sed -i '行号 s/原内容/替换后内容/列号' file
# 无行号,代表所有行
# 无列号代表第一个
sed -i '行号 s/原内容/替换后内容/g' file
# g,替换所有
sed -i '行号 s#原内容#&新增信息#列号' [文件名]
# &代表原内容
|
1
2
3
4
5
6
|
sed -i 's#sed#SED#' sed.txt
sed -i '2s#SED#sed#' sed.txt
sed -i 's#SED#sed#2' sed.txt # 第二个匹配到的改变
ip a show ens33 | sed -n '3p' | sed -r 's#.*inet (.*) brd.*#\1#'
10.0.0.14/24
|
追加与插入;\,注意是反斜杠
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
sed -i '行号 a\增加的内容' 文件名 # sed -i '行号 a\增加的内容' 文件名
sed -i '1,3a\增加内容' 文件名 # 范围追加
sed -i '行号 i\增加的内容' 文件名 # 将内容插入到指定的行
sed -i '1,3i\增加内容' 文件名 # 范围插入
# \ 的作用
[root@ubuntu2204 ~]# sed '2a *******' test.txt
aaa
bbb
*******
ccc
bbb
[root@ubuntu2204 ~]# sed '2a\ *******' test.txt
aaa
bbb
*******
ccc
bbb
|
删除
1
2
|
sed -i '行号 d' 文件名
sed -i '1,3d' 文件名
|
替换整行
1
2
3
4
5
6
7
|
sed -i '行号 c\内容' 文件名
sed -i '1,3c\内容' 文件名 # 将 1-3 行替换为‘内容’一行;不是每行都替换
[root@rocky9 ~]# head -n 1 /etc/passwd | sed -n 's/root/&user/1p'
rootuser:x:0:0:root:/root:/bin/bash
[root@rocky9 ~]# head -n 1 /etc/passwd | sed -n 's/root/&user/gp'
rootuser:x:0:0:rootuser:/rootuser:/bin/bash
|
加载保存
1
2
3
4
|
sed -i '行号 r 文件名 1' 文件名
sed -i '1,3r 文件名 1' 文件名 #每行后都加载
sed -i '行号 w 文件名' 文件名
|
题
1
2
3
4
5
|
ls | grep -Ev 'f-(1|3|5|7)\.txt' | sed -n 's/.*/rm &/p' | bash
[root@ubuntu2204 ~]# ls
f-1.txt f-3.txt f-5.txt f-7.txt
ls | grep -Ev 'f-(1|3|5|7)\.txt' | sed -En 's/(.*)/rm \1/p' | bash
|
1
2
3
4
5
6
7
8
9
10
11
|
sed -n '/^$/! p' nginx.conf # 空行不打印
sed -rn '/^(#|$)/! p' nginx.conf # 过滤掉空行和注释行
# 将非#开头的行加#
sed -rn ‘s/^[^#]/#&/p’ fstab
sed -rn '/^#/! s@^@#@p' fstab
sed -rn 's/^[^#](.*)/#\1/p' fstab
# 添加了 net.ifnames = 0
sed -Ei.bak 's/^(GRUB_CMDLINE_LINUX =.*)"$/\1 net.ifnames = 0 "/' /etc/default/grub
sed -Ei '/^GRUB_CMDLINE_LINUX/s#"$# net.ifnames = 0 "#' /etc/default/grub
|
^(#|$):匹配以 # 开头的注释行或空行。
^:匹配行的开头。#:表示注释行。$:匹配空行。( ... ):分组,# 或 $,即匹配注释或空行。
1
2
3
4
5
|
echo "/etc/sysconfig/network" |sed -r 's#(^/.*/)([^/]+/?)#\1#'
/etc/sysconfig/
echo "/etc/sysconfig/network" |sed -r 's#(^/.*/)([^/]+/?)#\2#'
network
|
s#(^/.\*/)([^/]+/?)#\1#:替换命令,用正则表达式匹配并替换。
(^/.\*/):匹配以 / 开头的路径,直到最后一个斜杠 / 之前。这里用括号将其分组为 \1,表示路径的父目录。([^/]+/?):匹配最后一个文件或目录的名称,[^/]+ 表示一个或多个非斜杠字符。\1:替换内容,仅保留第一个分组(即父目录路径部分),去除最后一个文件或目录的名称。
[^/]+:
[^/]:匹配除斜杠 / 之外的任何字符。方括号内的 ^ 表示“非”或“排除”。+:表示前面的模式(即 [^/])匹配一次或多次。因此,[^/]+ 匹配连续的、非斜杠的字符序列,代表路径中的最后一个文件或目录名称。
/?:
/:匹配路径中的斜杠。?:表示前面的 / 是可选的,即可以匹配零次或一次。- 所以
/? 表示最后的文件或目录名后面可以带有一个斜杠,也可以没有。
1
2
3
|
sed '/^#/d;/^$/d' nginx.conf
sed -r -e " s/listen.*;/listen\t $port;/" -e '/server_name/c\\tserver_name'$(hostname):$port';' nginx.conf
|
awk
过滤、提取、运算为一体
每一行是一条记录
每一列是一个字段
字段与字段的分隔符默认是一个或多个空格或tab制表符.
工作方式是逐行
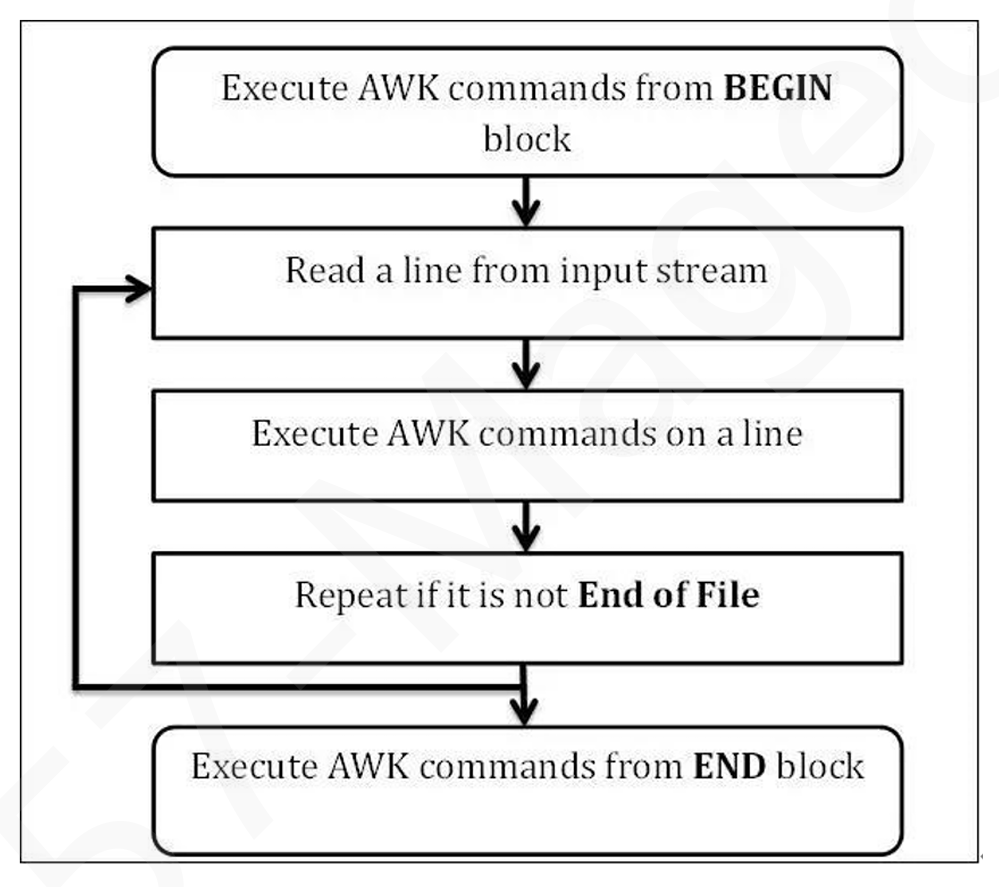
1
2
3
|
awk [参数] 'BEGIN 段 [动作] END 段' [文件名]
-F # 指定分隔符
-v # 设置内置变量
|
内置变量
1
2
3
4
5
6
7
8
9
10
11
12
13
|
FILENAME # 当前文件名
FS # 输入,字段分隔符 Field Separator
OFS # 输出,字段分隔符 Output Field Separator
RS # 输入,行分隔符 Record Separator
ORS # 输出,行分隔符 Output Record Separator
NF # 每行对应的字段数 Number of Fields
NR # 行号 Number of Records
FNR # 各个文件的行号 File Number of Records
ARGC # 命令参数个数
ARGV [n] # 命令参数内容
|
print
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$0 # 整行,不分割
$1 # 第一列
$n # 第 n 列
$NF # 最后一个列
NR # 行号
awk -v OFS =':' '{print $0}' awk
nihao awk1 awk2 awk3
nihao awk4 awk5 awk6
nihao awk7 awk8 awk9
awk -v OFS =':' '{print $1,$ 2}' awk
nihao: awk1
nihao: awk4
nihao: awk7
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
awk '{print $1"\t"$ 3}' awk.txt
# 动作执行的次数与文件行数一致
awk '{print "hello awk"}' awk
# 指定输出行数
awk 'NR >= 2 && NR <= 4 {print NR, "hello awk"}' awk
awk -F '[:/.]+' '{for (i = 1; i <= 3; i++) printf "%s ", $i; print ""}' domain
awk '{printf "%d--%s--%s\n", NR, $1,$ NR}' awk
awk 'BEGIN{print 2*3}'
6
awk '{print NR, $1"\t"$ 3}{print NR,$2}' awk
1 nihao awk2
1 awk1
2 nihao awk5
2 awk4
3 nihao awk8
3 awk7
4 awk11
4
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
awk -F ":" '
BEGIN {
printf "--------------------------\n%-17s|%19s|\n---------------------------\n", "用户名", "shell 类型"
}
{
printf "%-20s|%21s|\n---------------------------\n", $1, $ 7
}
END {
printf "用户总数: %2d\n", NR
}' /etc/passwd
# %s
# %20s 20 个字符宽度,中文占 2 字符宽度
# %-20s 左对齐,默认右对齐
--------------------------
用户名 | shell 类型|
---------------------------
root | /bin/bash|
---------------------------
bin | /usr/sbin/nologin|
---------------------------
daemon | /usr/sbin/nologin|
---------------------------
adm | /usr/sbin/nologin|
---------------------------
lp | /usr/sbin/nologin|
---------------------------
sync | /bin/sync|
---------------------------
shutdown | /sbin/shutdown|
---------------------------
halt | /sbin/halt|
---------------------------
mail | /usr/sbin/nologin|
---------------------------
operator | /usr/sbin/nologin|
---------------------------
games | /usr/sbin/nologin|
---------------------------
ftp | /usr/sbin/nologin|
---------------------------
nobody | /usr/sbin/nologin|
---------------------------
systemd-coredump | /sbin/nologin|
---------------------------
saslauth | /sbin/nologin|
---------------------------
libstoragemgmt | /sbin/nologin|
---------------------------
rpc | /sbin/nologin|
---------------------------
tss | /sbin/nologin|
---------------------------
dhcpd | /sbin/nologin|
---------------------------
dnsmasq | /usr/sbin/nologin|
---------------------------
sshd | /sbin/nologin|
---------------------------
dbus | /sbin/nologin|
---------------------------
polkitd | /sbin/nologin|
---------------------------
unbound | /sbin/nologin|
---------------------------
qemu | /sbin/nologin|
---------------------------
rpcuser | /sbin/nologin|
---------------------------
cockpit-ws | /sbin/nologin|
---------------------------
cockpit-wsinstance | /sbin/nologin|
---------------------------
chrony | /sbin/nologin|
---------------------------
tcpdump | /sbin/nologin|
---------------------------
nginx | /sbin/nologin|
---------------------------
ntp | /sbin/nologin|
---------------------------
noob | /bin/bash|
---------------------------
loong | /bin/bash|
---------------------------
用户总数: 34
|
1
2
3
4
5
6
7
|
[root@loong vim]# awk 'BEGIN{FIELDWIDTHS = "5 2 8"}NR == 1{print $1,$ 2,$3}' /etc/passwd
root: x: 0:0:Supe
[root@loong vim]# cat /etc/passwd
root:x:0:0:Super User:/root:/bin/bash
# FIELDWIDTHS = "5 2 8"
# 5 个字符为 $1;2=$ 2;8 =$3
|
自定义变量
1
2
3
4
5
|
awk -v var1 = abc 'BEGIN{print var1}'
awk -v var1 = abc -v VAR1 = 123 'BEGIN{print var1, VAR1}'
awk 'BEGIN{name = "shuji"; print name}'
awk -v var1 = abc 'BEGIN{print var1; var1 = "def"; print var1}{print var1}' /etc/os-release
|
匹配运算
1
2
3
4
5
|
~
!~
awk -F ':' '$1 ~ "^[a-d].*" {print $ 0}' /etc/passwd
awk -F ':' '$1 !~ "^[a-d].*" {print $ 0}' /etc/passwd
|
x?x:x
ture前
false后
1
|
awk -F: '{$3>=1000?utype="Common":utype="Sys"; printf "%-20s:%12s\n",$ 1, utype}' /etc/passwd
|
条件判断
if-else
1
|
awk -F: '{if($3<=100){print "<=100",$ 3}else if ($3<=1000){print "<=1000",$ 3} else{print "> 1000",$3}}' /etc/passwd
|
swich-case
1
|
awk -F: '{switch($3){case 0:print "root",$ 3; break; case /^[1-9][0-9]{0,2}$|1000/:print "sys user",$ 3; break; default: print "common user",$3; break;}}' /etc/passwd
|

while
1
2
3
|
awk -v i = 1 -v sum = 0 'BEGIN{while(i <= 100){sum+= i; i++}; print sum}'
awk 'BEGIN{ total = 0; i = 1; do{total+= i; i++;}while(i <= 100); print total}'
|
for
1
2
3
4
5
6
7
8
9
10
|
echo 'dsFUs34tg*fs5a8ar%$#@' | awk -F "" '
{
str = "" # 初始化 str 为空字符串
for (i = 1; i <= NF; i++) {
if ($i ~ /[0-9]/) { # 如果 $ i 是数字字符
str = (str $i) # 拼接数字字符到 str
}
}
print str # 输出拼接后的数字字符串
}'
|
continue 和 break
next
下一行处理(awk自身循环)
数组
判断索引存不存在
1
2
|
awk 'BEGIN{array ["i"] = "x"; array ["j"] = "y" ; print "i" in array, "y" in array }'
0 1
|

遍历数组
1
2
3
4
5
6
7
8
|
awk 'BEGIN {
a ["x"] = "welcome"
a ["y"] = "to"
a ["z"] = "Magedu"
for (i in a) {
print i, a [i]
}
}'
|
1
2
3
4
5
6
7
8
9
|
awk '{
ip[$1]++
} END {
for (i in ip) {
if (ip [i] >= 1000) {
system("iptables -A INPUT -s \"" i "\" -j REJECT")
}
}
}' nginx.access.log-20200428
|


内置函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int() # 转为 int
sqrt() # 平方根
srand() # 设置 rand 种子
rand() # 随机数
# 字符串类
length()
strtonum() # 0 开头,8 进制;0x 开头,16 进制
tolower()
toupper()
index(str, substr) # 在 str 中查找 substr,有,返回索引;无,返回 0
split(str, arr, 分隔符)
match()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
awk 'BEGIN{a = sprintf("%s-%d-%s", "abc",23, "ert"); print a}'
awk 'BEGIN{v = "nsfadsafdsaf"; print length(v)}'
awk 'BEGIN{str = "nsfad"; print index(str, "ns")}'
1
awk 'BEGIN{v = "abcdefgh"; print substr(v,3,3)}'
cde
awk 'BEGIN{split("abc-def-gho-pq", arr, "-", seps); print length(arr), arr [3], seps [1]}'
4 gho -
awk 'BEGIN{str = "safdsajfkdsajlfjdsl"; print match(str," j.*s ")}'
7
awk 'BEGIN{str = "safdsajfkdsajlfjdsl"; match(str," j.*s ", arry); print arry [0]}'
jfkdsajlfjds
|
1
2
3
4
5
6
7
8
|
systime()
awk 'BEGIN{print strftime()}'
# 系统命令
system(cmd)
awk 'BEGIN{system("hostname")}'
isarray()
|
1
2
3
4
|
[root@loong vim]# awk 'BEGIN{v =("aa" "bb" 11); print isarray(v)}'
0
[root@loong vim]# awk 'BEGIN{v [1] =("aa" "bb" 11); print isarray(v)}'
1
|
自定义函数
1
2
3
4
5
|
function name ( parameter, parameter, ... ) {
statements
return expression
}
awk 'function test(){print "hello test func"}BEGIN{test()}'
|